 Micro-core architectures combine many simple, low power, cores on a single processor package. These micro-core architectures, provide significant parallelism and performance for low power, which is great, but a major limitation is programmer productivity. Typically developers must write their code in C, linked to low level libraries, and then run it bare-metal. Furthermore they must possess a deep understanding of the technology and address esoteric aspects including ensuring consistency with a (sometimes very) weak memory model, aligning data to word boundaries correctly, and the lack of basic features such as IO. As such, even the few experts who are able to program these chips struggle when it comes to obtaining good performance.
Micro-core architectures combine many simple, low power, cores on a single processor package. These micro-core architectures, provide significant parallelism and performance for low power, which is great, but a major limitation is programmer productivity. Typically developers must write their code in C, linked to low level libraries, and then run it bare-metal. Furthermore they must possess a deep understanding of the technology and address esoteric aspects including ensuring consistency with a (sometimes very) weak memory model, aligning data to word boundaries correctly, and the lack of basic features such as IO. As such, even the few experts who are able to program these chips struggle when it comes to obtaining good performance.
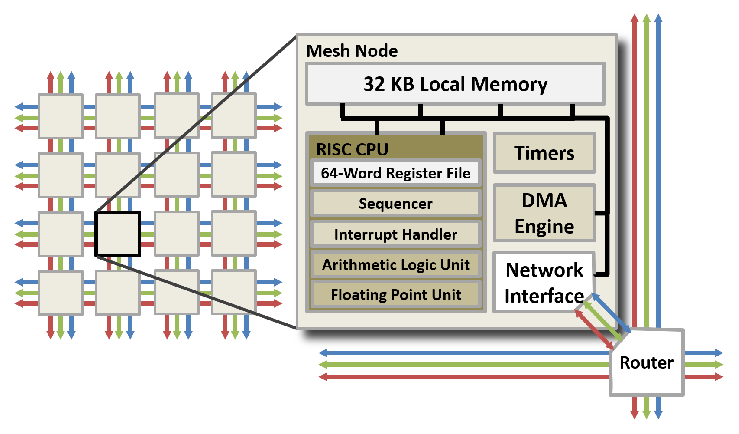 In this work we initially focused on the Adapteva Epiphany III, which is illustrated on the left and provides a chip with 16 cores, each with 32KB of scratch-pad memory (and access to 32MB of much slower, host DRAM). The big challenge here was programmer adoption, and as such we decided to develop an implementation of Python for the technology. Known as ePython and hosted on Github (here), I worked on this with one of my PhD students, Maurice Jamieson, and our initial example was a simple hello world code, but it enabled the programmer to go from zero to hero (i.e. writing a first program for the Epiphany without any prior experience) in less than a minute. This provided significant productivity benefits, and our initial aim for ePython was around education and fast-prototyping.
In this work we initially focused on the Adapteva Epiphany III, which is illustrated on the left and provides a chip with 16 cores, each with 32KB of scratch-pad memory (and access to 32MB of much slower, host DRAM). The big challenge here was programmer adoption, and as such we decided to develop an implementation of Python for the technology. Known as ePython and hosted on Github (here), I worked on this with one of my PhD students, Maurice Jamieson, and our initial example was a simple hello world code, but it enabled the programmer to go from zero to hero (i.e. writing a first program for the Epiphany without any prior experience) in less than a minute. This provided significant productivity benefits, and our initial aim for ePython was around education and fast-prototyping.
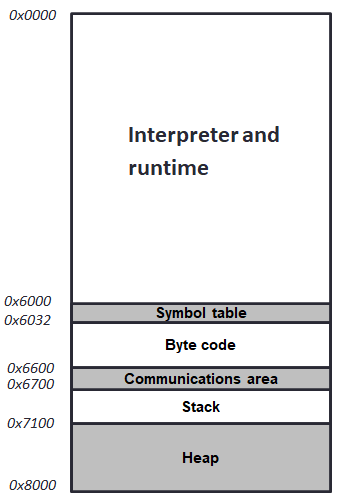 With only 32KB of scratch-pad memory, code size is everything. We limited the size of the ePython interpreter and runtime to be just 24KB, and to our knowledge this is by far the smallest Python implementation in the world! However, we provide rich functionality and enables the writing of parallel codes across the cores by a message passing, shared memory, or task-based approach. These two facets are the major difference from MicroPython, which is much larger (greater than 512KB) and not specifically designed for parallelism. The micro-cores are running bare metal, and as such ePython sets up the CPU memory map. This is illustrated on the right, and the remaining 8KB of memory is partitioned between the programmer’s Python byte code and data. For performance, we aim to hold as much as possible in this memory space, but do allow it to overflow to the much slower (around 5 times) 32MB of external DRAM if necessary. There is also a full garbage collector (which accounts for around 1KB of our overall interpreter and runtime 24KB size) which clears up orphaned memory blocks.
With only 32KB of scratch-pad memory, code size is everything. We limited the size of the ePython interpreter and runtime to be just 24KB, and to our knowledge this is by far the smallest Python implementation in the world! However, we provide rich functionality and enables the writing of parallel codes across the cores by a message passing, shared memory, or task-based approach. These two facets are the major difference from MicroPython, which is much larger (greater than 512KB) and not specifically designed for parallelism. The micro-cores are running bare metal, and as such ePython sets up the CPU memory map. This is illustrated on the right, and the remaining 8KB of memory is partitioned between the programmer’s Python byte code and data. For performance, we aim to hold as much as possible in this memory space, but do allow it to overflow to the much slower (around 5 times) 32MB of external DRAM if necessary. There is also a full garbage collector (which accounts for around 1KB of our overall interpreter and runtime 24KB size) which clears up orphaned memory blocks.
Offloading code from the host
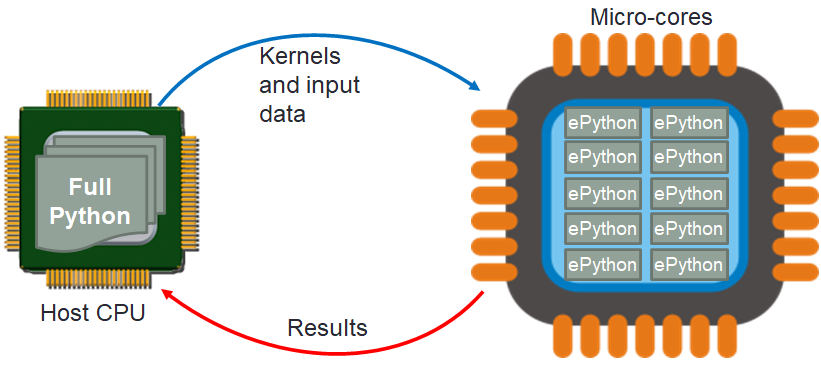
The initial version of ePython ran directly from the command line, with the programmer providing their script as a command line argument. However, we soon realised that another useful mode of operation would be to have a large Python code running in any Python interpreter, such as CPython, and then for the programmer to select specific functions to offload, with the mechanics of how this is achieved and the associated data movement all abstracted. This is illustrated below, where effectively ePython is an execution engine running on each micro-core, directed by the host to execute specific Python kernels as appropriate. ePython supports the passing of functions as first class values, so it is fairly easy to use this mechanism for marshalling and control of the kernels. Furthermore when it comes to ePython running on each core, there is nothing particularly special about communicating with other cores. As such, an additional ePython engine is created by the host, which to all intents and purposes looks like any other core. This is then used to marshal communication between ePython on the micro-cores (who think they are communicating with another micro-core, but in-fact ti is the host) and the host’s external Python interpreter.
 The code snippet to the right illustrates some very simple Python code running on the host under any Python interpreter such a CPython. The my_kernel function is annotated with an offload decorator, to be found in the epython module, and this instructs Python that all executions of this function should be offloaded to the micro-cores. When the function is called, it is executed on the micro-cores, with any input data transferred on and result data copied off. There are numerous additional features supported, such as asynchronous execution, queuing of kernels, device resident data, and execution of a subset of cores.
The code snippet to the right illustrates some very simple Python code running on the host under any Python interpreter such a CPython. The my_kernel function is annotated with an offload decorator, to be found in the epython module, and this instructs Python that all executions of this function should be offloaded to the micro-cores. When the function is called, it is executed on the micro-cores, with any input data transferred on and result data copied off. There are numerous additional features supported, such as asynchronous execution, queuing of kernels, device resident data, and execution of a subset of cores.
Expanding to other architectures
The Epiphany is just one example of a micro-core architecture, and in late 2017 Adapteva stopped actively developing the technology and suspended operations. By this time ePython was included in the standard software build that shipped with the product, and with over 15,000 Epiphanies sold then it was receiving reasonable usage. However, clearly if we did not adopt other technologies then at some point ePython would become less moribund.
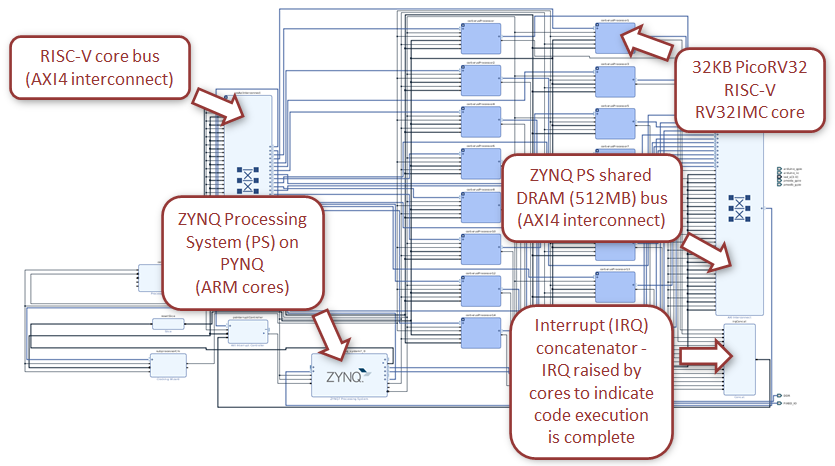
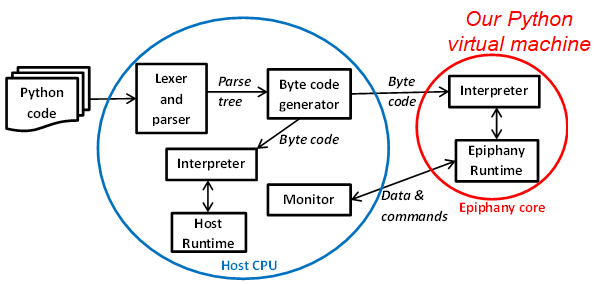 In-fact targeting other architectures was made easier because of the way in which we had structured the ePython code, where much was architecture agnostic including the interpreter itself. To add a new architecture only requires two new things, an architecture specific runtime that will run on the device (implementing a predefined set of services), and explicit support in the host to communicate with the device. The structure is illustrated on the left, where the red circle contains functionality running on the micro-core (the Epiphany in this case), communicating with the host via a monitor. We therefore exploited this to add support for the Xilinx MicroBlaze and RISC-V PicoRV32. These are especially interesting as. unlike the Epiphany, these are not physical chips but instead soft-cores which configure an FPGA to look like a design of CPU. Because of the soft nature, we can configure these CPUs in many different ways, which extends to how many are contained on the FPGA and how they are interconnected. For instance, Maurice my PhD student, developed a multi-core RISC-V design called Cerberus whose Vivado block design is illustrated below. This packages 16 PicoRV32 cores (each with 32KB RAM), which interact with each other and the host, and execute ePython across them.
In-fact targeting other architectures was made easier because of the way in which we had structured the ePython code, where much was architecture agnostic including the interpreter itself. To add a new architecture only requires two new things, an architecture specific runtime that will run on the device (implementing a predefined set of services), and explicit support in the host to communicate with the device. The structure is illustrated on the left, where the red circle contains functionality running on the micro-core (the Epiphany in this case), communicating with the host via a monitor. We therefore exploited this to add support for the Xilinx MicroBlaze and RISC-V PicoRV32. These are especially interesting as. unlike the Epiphany, these are not physical chips but instead soft-cores which configure an FPGA to look like a design of CPU. Because of the soft nature, we can configure these CPUs in many different ways, which extends to how many are contained on the FPGA and how they are interconnected. For instance, Maurice my PhD student, developed a multi-core RISC-V design called Cerberus whose Vivado block design is illustrated below. This packages 16 PicoRV32 cores (each with 32KB RAM), which interact with each other and the host, and execute ePython across them.
Unlimited data and code size
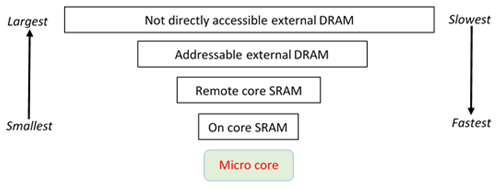 One of the challenges of using micro-cores for real-world applications is that the available memory space quickly becomes exhausted with data and code. This is a challenge, however the problem is compounded by the fact that these architectures typically expose their memory in a hierarchical fashion. The diagram on the right illustrates the memory hierarchy for the Epiphany, where very fast but small memory spaces are nearest the core, and larger but slower are further away (and some of which are inaccessible directly by the micro-cores). We therefore adopted the abstraction of memory kinds, where the programmer decorates data resident on the host with a kind, which both denotes where in this memory space the data should live and also provides the underlying functionality to access and move it. We also modified the semantics of offloaded kernel arguments to be that of pass by reference, rather than pass by value. This means that the underlying system can stream in data (worst case on-demand, but prefetching is provided for performance reasons) to the micro-core. For a machine learning benchmark, we were able to stream in hundreds of MB of data into the tiny memory spaces, with the cores performing linear algebra operations, the result streamed out and that same space then occupied with more data.
One of the challenges of using micro-cores for real-world applications is that the available memory space quickly becomes exhausted with data and code. This is a challenge, however the problem is compounded by the fact that these architectures typically expose their memory in a hierarchical fashion. The diagram on the right illustrates the memory hierarchy for the Epiphany, where very fast but small memory spaces are nearest the core, and larger but slower are further away (and some of which are inaccessible directly by the micro-cores). We therefore adopted the abstraction of memory kinds, where the programmer decorates data resident on the host with a kind, which both denotes where in this memory space the data should live and also provides the underlying functionality to access and move it. We also modified the semantics of offloaded kernel arguments to be that of pass by reference, rather than pass by value. This means that the underlying system can stream in data (worst case on-demand, but prefetching is provided for performance reasons) to the micro-core. For a machine learning benchmark, we were able to stream in hundreds of MB of data into the tiny memory spaces, with the cores performing linear algebra operations, the result streamed out and that same space then occupied with more data.
Currently we are working on supporting code of arbitrary size by native compilation and dynamic loading. Instead of running via an interpreter, the programmers code is compiled into a native executable and the links between the different parts are entirely dynamic. A bootloader is placed onto the micro-cores, and as specific functions are requested then these are retrieved from the host, connected to the necessary on-core memory, and then executed. These functions can either stay resident on the micro-cores, or be flushed out if memory is exhausted. Whilst development on this aspect of ePython is on-going, early tests indicate that we can achieve around 90% the performance of directly written C code, and encounter a minimum memory size of around 6KB.
Related publications
- Having your cake and eating it: Exploiting Python for programmer productivity and performance on micro-core architectures using ePython. Jamieson, M., Brown, N. & Liu, S. In Proceedings of the 19th Python in Science Conference : SciPy 2020 (more info)
- High level programming abstractions for leveraging hierarchical memories with micro-core architectures. Jamieson, M. & Brown, N. In Journal of Parallel and Distributed Computing (more info)
- Eithne: A framework for benchmarking micro-core accelerators. Jamieson, M. & Brown, N. Poster in Supercomputing 2019 (more info)
- Leveraging hierarchical memories for micro-core architectures. Brown, N. & Jamieson, M. In the 5th Exascale Applications and Software Conference (more info)
- ePython: An Implementation of Python Enabling Accessible Programming of Micro-Core Architectures. Brown, N. In Computing Insight UK (more info)
- Offloading Python kernels to micro-core architectures. Brown, N. Poster in Supercomputing 2017 (more info)
- ePython: An implementation of Python for the many-core Epiphany coprocessor. Brown, N. In the 6th Workshop on Python for High-Performance and Scientific Computing (more info)