This page provides a summary of the different research areas that I am interested in and summarises some of my activities. The results of these projects can be seen in my publications.
Emerging architectures for HPC
A major component of my research is exploring the role that new, upcoming, hardware architectures can play in accelerating high performance computing codes. Often orders of magnitude more energy efficient than existing technologies, the challenge is often how to exploit these most effectively. Whether it is processing workloads centrally on supercomputers in a data centre, or out at the edge, requirements are being driven by scientific and societal ambition that uniquely suit these new types of hardware.
I am a Co-I on the £1.7M EPSRC funded HPC-R project which is, in part, exploring a co-design approach to leveraging novel architectures for energy efficient HPC. This is currently focusing on the following technologies.
RISC-V for HPC
 RISC-V is an open ISA and with over 20 billion RISC-V devices in existence, it has enjoyed phenomenal growth since it was developed over a decade ago. I was PI of the EPSRC funded RISC-V testbed which aimed to explore and popularise RISC-V in the context of HPC. This system has been endorsed as a RISC-V ecosystem lab by RISC-V International who are the standards body.
RISC-V is an open ISA and with over 20 billion RISC-V devices in existence, it has enjoyed phenomenal growth since it was developed over a decade ago. I was PI of the EPSRC funded RISC-V testbed which aimed to explore and popularise RISC-V in the context of HPC. This system has been endorsed as a RISC-V ecosystem lab by RISC-V International who are the standards body.
I have undertaken extensive benchmarking of RISC-V CPUs, including the first to benchmark the SG2042 and SG2044 for HPC, as well as being the first to port scientific computing workload to a RISC-V accelerator. In addition to my research activities I am chair of the RISC-V International HPC SIG, am a RISC-V Ambassador and lead organiser for the RISC-V HPC workshop series which has been at a wide range of top HPC conferences including ISC, SC, HPC Asia, and HIPC.
FPGAs and CGRAs
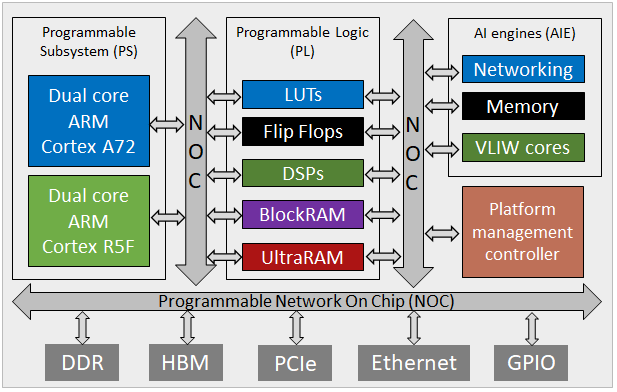 More capable hardware make FPGAs a serious proposition for HPC like never before. However, in order to gain good (or even acceptable) performance we need to rethink our algorithms and move from an imperative, Von Neumann, style to a dataflow design. It is this area, the design and development of new dataflow techniques, that I find most interesting within the context of FPGAs and have led the porting of numerous HPC codes onto FPGAs across several domains (e.g. finance, CFD, atmospheric modelling). I was a Co-I on the EPSRC funded FPGA testbed, which aimed to make FPGAs more accessible for HPC developers.
More capable hardware make FPGAs a serious proposition for HPC like never before. However, in order to gain good (or even acceptable) performance we need to rethink our algorithms and move from an imperative, Von Neumann, style to a dataflow design. It is this area, the design and development of new dataflow techniques, that I find most interesting within the context of FPGAs and have led the porting of numerous HPC codes onto FPGAs across several domains (e.g. finance, CFD, atmospheric modelling). I was a Co-I on the EPSRC funded FPGA testbed, which aimed to make FPGAs more accessible for HPC developers.
CGRAs provide coarse grained reconfigurability and, typically providing processing cores within a flexible interconnect, are becoming more popular. I was PI of an EPSRC funded CGRA project, which explored accelerating HPC codes on the Cerebras CS-2 and AMD Xilinx AI engines. As part of this research I undertook the first study in leveraging AI engines for HPC workloads which was published at ISFPGA.
![]() I was awarded a Royal Society of Edinburgh personal research fellowship which ran in 2024 and 2025, this explored greener weather forecasting on supercomputers. Focusing on Met Office workloads, the first major area was leveraging FPGAs in the network for undertaking in-situ data post-processing and reduction, a task that is currently done by CPUs.
I was awarded a Royal Society of Edinburgh personal research fellowship which ran in 2024 and 2025, this explored greener weather forecasting on supercomputers. Focusing on Met Office workloads, the first major area was leveraging FPGAs in the network for undertaking in-situ data post-processing and reduction, a task that is currently done by CPUs.
HPC compilers and programming models
A major motivation of my research is the grand challenge of how we can enable scientists and engineers to most effectively program current and future generation HPC machines. Given the large degree of parallelism, and heterogeneous nature of our supercomputers, this currently requires deep expertise. Put simply, scientists want to worry about their problem rather than the tricky, low level details of parallelism, and indeed if we do not solve this problem then the benefit we gain from exascale supercomputers will likely be limited.
I am a Co-I on the £1.5M EPSRC funded CONTINENTS centre to centre collaboration with the US National Centre for Atmospheric Research (NCAR), one area of focus is on compiler technologies for HPC.
xDSL: The cross domain DSL ecosystem
![]() I was a Co-I on, and knowledge exchange coordinator of, the £1M EPSRC funded xDSL project. The fundamental issue we looked to address is that Domain Specific Languages (DSLs) are one way in which we can solve the HPC programming challenge, however underlying DSL compiler ecosystems tend to be heavily siloed which heightens user risk and results in maintenance burdens. To this end we developed a common ecosystem for DSLs based around MLIR/LLVM, enabling DSLs to become a thin abstraction layer atop this existing well supported technology. xDSL continues, with over 1 million downloads.
I was a Co-I on, and knowledge exchange coordinator of, the £1M EPSRC funded xDSL project. The fundamental issue we looked to address is that Domain Specific Languages (DSLs) are one way in which we can solve the HPC programming challenge, however underlying DSL compiler ecosystems tend to be heavily siloed which heightens user risk and results in maintenance burdens. To this end we developed a common ecosystem for DSLs based around MLIR/LLVM, enabling DSLs to become a thin abstraction layer atop this existing well supported technology. xDSL continues, with over 1 million downloads.
Using two DSLs to drive our experiments, we not only developed a Python-based MLIR compiler framework but furthermore numerous HPC focused dialects including the MPI dialect which has now been upstreamed into MLIR. Furthermore, we found that by leveraging MLIR it is often possible to consolidate many of these domain specific compilers with general purpose ones and this resulted in an ASPLOS paper. We also developed a generic flow from Fortran, in Flang, to the upstream MLIR dialects. Whilst the purpose of this was to generally demonstrate performance improvements from core MLIR, it has also opened up a range of additional flexibility that is useful for driving novel architectures.
I am a Co-I on the ARCHER2 funded eCSE project which is using MLIR and xDSL to develop a Domain Specific Language (DSL) for the ExaHyPE hyperbolic PDE solver framework to raise programmer productivity and enable automatic parallelism optimisation across CPUs and GPUs.
Programmer productivity and performance on emerging architectures
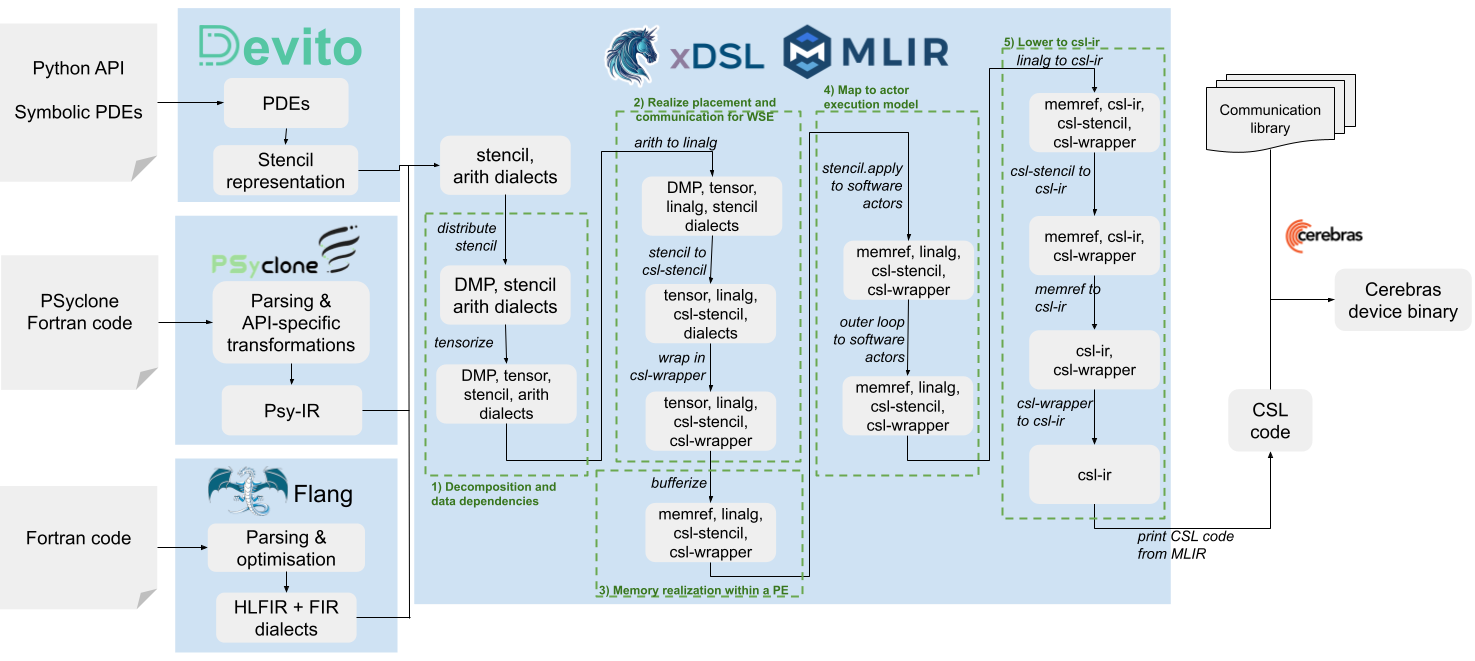 The Cerebras Wafer Scale Engine (WSE), AMD’s AI Engines (AIEs) and Tenstorrent’s Tensix architecture are just three examples of the wide range of specialised accelerators we are seeing for AI workloads (which are typically focused on inference). At their heart these technologies provide specialised hardware for optimising linear algebra operations and data movement. That same hardware specialisation can also be beneficial for general purpose scientific computing workloads. However, whilst this hardware has demonstrated performance and energy benefits, the devil is in the detail especially enabling programmers to effectively write code for these architectures to unlock this potential. Leveraging MLIR and xDSL, a major part of my current research activities is to explore not only how the compiler can undertake automatic algorithmic transformation for this type of hardware, but furthermore what infrastructure can be shared between these specialised compilers. The ultimate objective is for scientific computing programmers to be able to deploy their codes effectively and unchanged across a wide range of architectures. This has been the second area of focus for my Royal Society of Edinburgh personal research fellowship and has led to ASPLOS and CCGrid papers amongst others.
The Cerebras Wafer Scale Engine (WSE), AMD’s AI Engines (AIEs) and Tenstorrent’s Tensix architecture are just three examples of the wide range of specialised accelerators we are seeing for AI workloads (which are typically focused on inference). At their heart these technologies provide specialised hardware for optimising linear algebra operations and data movement. That same hardware specialisation can also be beneficial for general purpose scientific computing workloads. However, whilst this hardware has demonstrated performance and energy benefits, the devil is in the detail especially enabling programmers to effectively write code for these architectures to unlock this potential. Leveraging MLIR and xDSL, a major part of my current research activities is to explore not only how the compiler can undertake automatic algorithmic transformation for this type of hardware, but furthermore what infrastructure can be shared between these specialised compilers. The ultimate objective is for scientific computing programmers to be able to deploy their codes effectively and unchanged across a wide range of architectures. This has been the second area of focus for my Royal Society of Edinburgh personal research fellowship and has led to ASPLOS and CCGrid papers amongst others.
ML benchmarking
I am a Co-I on the £2M ARIA funded Tracking Evolving AI and Systems (TEAS) benchmarking project. A collaboration between the School of Informatics, EPCC and Imperial College London, we are developing an ML inference benchmarking suite that comprises latest ML workloads. This suite can then be used by vendors and researchers as a basis for comparing next-generation ML hardware and other technologies across the current state of the art. Publishing a scoreboard across a range of current architectures, a major part of this project is to also port these models to emerging ML architectures such as the Cerebras CS-3. In EPCC we bring significant expertise in benchmarking techniques, and one key outcome that we aim for is to bring some of these from the HPC to ML domains.
Urgent supercomputing
![]() I led the interactive supercomputing work package on the €4M H2020 FETHPC VESTEC project and was responsible for ten deliverables. VESTEC ran between 2018 and 2022, and explored the fusion of real-time data with HPC for running urgent real-time workloads to better inform disaster response. Our case studies included forest fires and mosquito borne diseases, and my work package, which comprised around 100 months of effort over 7 partners, developed a technology providing federation of these interactive workloads across a range of supercomputers. A nice summary was published in IEEE Access.
I led the interactive supercomputing work package on the €4M H2020 FETHPC VESTEC project and was responsible for ten deliverables. VESTEC ran between 2018 and 2022, and explored the fusion of real-time data with HPC for running urgent real-time workloads to better inform disaster response. Our case studies included forest fires and mosquito borne diseases, and my work package, which comprised around 100 months of effort over 7 partners, developed a technology providing federation of these interactive workloads across a range of supercomputers. A nice summary was published in IEEE Access.
As part of this project I began the UrgentHPC workshop series that ran at SC19, SC20, SC21, and SC22. At the end of the project this initiative merged with the interactive HPC workshop series, and since then I have been involved in organising further workshops at ISC22 and ISC23, as well as a BoF at SC23.
HPC code acceleration
![]() I have worked with numerous organisations, developing and optimising their HPC codes, with my interests in developing new techniques for improving performance. For instance, I was the main developer of the Met Office NERC Cloud model (MONC) between 2014 and 2015, which is the Met Office’s high resolution atmospheric model which is used by them to explore weather phenomena at small scales and develop new parameterisations for their main weather forecasting model.
I have worked with numerous organisations, developing and optimising their HPC codes, with my interests in developing new techniques for improving performance. For instance, I was the main developer of the Met Office NERC Cloud model (MONC) between 2014 and 2015, which is the Met Office’s high resolution atmospheric model which is used by them to explore weather phenomena at small scales and develop new parameterisations for their main weather forecasting model.
The previous model was capable of modelling only around 10 million grid points, whereas this work increased capability to supporting simulation of tens of billions of grid points over many thousand CPU cores. In addition to the computation, a major challenge was in the refinement of raw data to generate higher level information which the scientists are interested in. I developed a novel in-situ approach, where CPU cores are shared between computation and data analysis, enabling an order of magnitude increase in the data processing that was possible. Since the initial development I have been a Co-I on several projects that have further enhanced the model and am PI on an ARCHER2 eCSE-GPU project that runs between 2025 and 2027 which is porting MONC to GPUs.
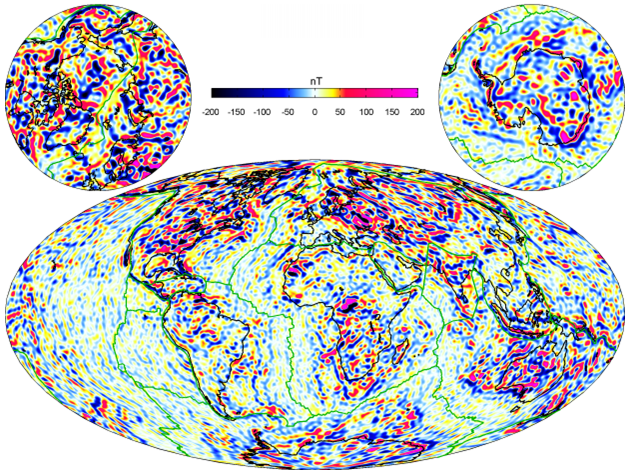 I have been a Co-I on a couple of projects with the British Geological Survey, optimising their geomagnetic models for modern supercomputers. For example their Model of the Earth’s Magnetic Environment (MEME) code predicts the changing geomagnetic environment but that the challenge was that this was only capable of handling a tiny fraction of the raw data which is available from swarm satellites and ground stations. In order to improve the accuracy of the model, and enable exploration of more challenging polar latitudes, it was desirable to increase the size of input data set and resolution. Fundamentally, underlying the core of this optimisation work was the development of a novel technique for parallel assembly of the matrix of equations, which had been extremely costly in the existing code base. Ultimately this work resulted in around a ten times increase in the size of data that could be handled by the code at a reduction of over 100 times the runtime that we published in CCPE.
I have been a Co-I on a couple of projects with the British Geological Survey, optimising their geomagnetic models for modern supercomputers. For example their Model of the Earth’s Magnetic Environment (MEME) code predicts the changing geomagnetic environment but that the challenge was that this was only capable of handling a tiny fraction of the raw data which is available from swarm satellites and ground stations. In order to improve the accuracy of the model, and enable exploration of more challenging polar latitudes, it was desirable to increase the size of input data set and resolution. Fundamentally, underlying the core of this optimisation work was the development of a novel technique for parallel assembly of the matrix of equations, which had been extremely costly in the existing code base. Ultimately this work resulted in around a ten times increase in the size of data that could be handled by the code at a reduction of over 100 times the runtime that we published in CCPE.
Machine learning
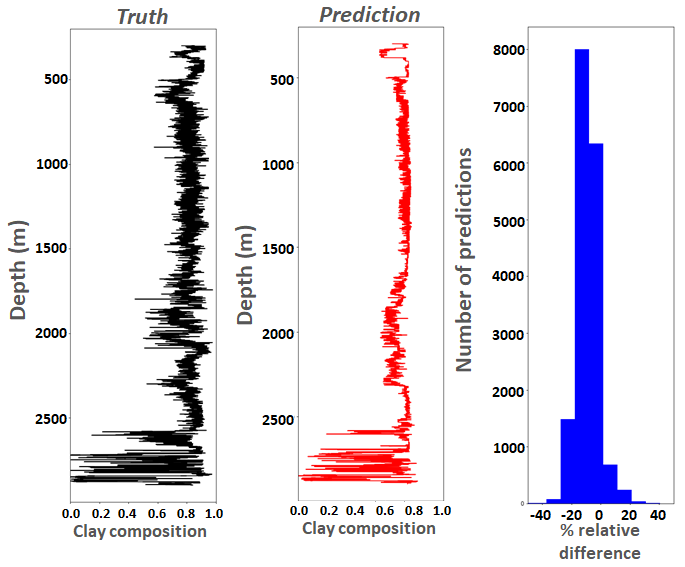 Whilst most of my interest around machine learning is in how best we can leveraging novel architectures at the edge for ML workloads, I was PI of a project which explored the use of ML for optimising petrophysical workflows of well log data. The objective was to enable better use of the human because manual interpretation of each well took around 7 days and there were thousands of wells that required processing. However, the petrophysicist was using their knowledge and expertise to identify and extract specific patterns in the raw data, and the hypothesis was that, based upon a large enough training set, it would be possible to train an ML model to identify these patterns. We leveraged boosted trees and deep neural networks, ultimately reduceing the overall well processing time down to around two days that we published in CCPE. After the project concluded the IP was sold to PGS which resulted in a follow on project where we explored tuning the ML algorithms for their workloads.
Whilst most of my interest around machine learning is in how best we can leveraging novel architectures at the edge for ML workloads, I was PI of a project which explored the use of ML for optimising petrophysical workflows of well log data. The objective was to enable better use of the human because manual interpretation of each well took around 7 days and there were thousands of wells that required processing. However, the petrophysicist was using their knowledge and expertise to identify and extract specific patterns in the raw data, and the hypothesis was that, based upon a large enough training set, it would be possible to train an ML model to identify these patterns. We leveraged boosted trees and deep neural networks, ultimately reduceing the overall well processing time down to around two days that we published in CCPE. After the project concluded the IP was sold to PGS which resulted in a follow on project where we explored tuning the ML algorithms for their workloads.