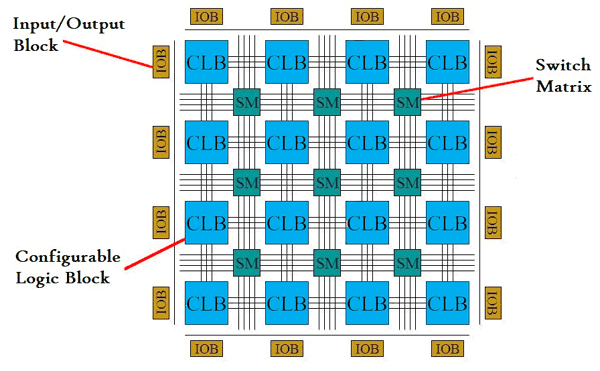
 Reconfigurable architectures, such as Field Programmable Gate Arrays (FPGAs), contain many configurable logic blocks sitting in a sea of interconnect. There are many uses, and indeed most people own at-least one of these unknowingly. Of most interest to me is that one can configure the electronics to look like an application, effectively executing a code directly at the electronics level. When one bears in mind the disconnect between the ISA and out-of-order micro-architecture of many modern CPUs, there are potentially numerous benefits to be gained by unifying how an application is designed to be executed by the programmer, and how it actually physically executes.
Reconfigurable architectures, such as Field Programmable Gate Arrays (FPGAs), contain many configurable logic blocks sitting in a sea of interconnect. There are many uses, and indeed most people own at-least one of these unknowingly. Of most interest to me is that one can configure the electronics to look like an application, effectively executing a code directly at the electronics level. When one bears in mind the disconnect between the ISA and out-of-order micro-architecture of many modern CPUs, there are potentially numerous benefits to be gained by unifying how an application is designed to be executed by the programmer, and how it actually physically executes.
 Primarily, I am interested in three things when it comes to reconfigurable architectures:
Primarily, I am interested in three things when it comes to reconfigurable architectures:
- Algorithmic transformations required to move from a Von Neumann style of computing to dataflow architecture
- The performance and energy benefits that can be delivered to applications by FPGAs
- High level programming models for enabling high(er) programmer productivity when writing high performance dataflow codes
Acceleration of HPC codes on FPGAs
This ties in with my first two interests in reconfigurable architectures, and through the EXCELLERAT EU funded Centre of Excellence (CoE) I am exploring the potential acceleration of scientific codes on FPGAs. Focusing on a few applications and benchmarks, we started with an initial focus on getting something running correctly, and then optimising to compare performance and power efficiency against other architectures.
Whilst each application is of course different, we consistently see that there are significant differences in performance between the first, Von Neumann style and the final dataflow HLS code. These can range as large as a 5000 times difference in performance, and an interesting research question is the correct approaches to obtain this optimal performance in the first instance.
Accelerating atmospheric advection
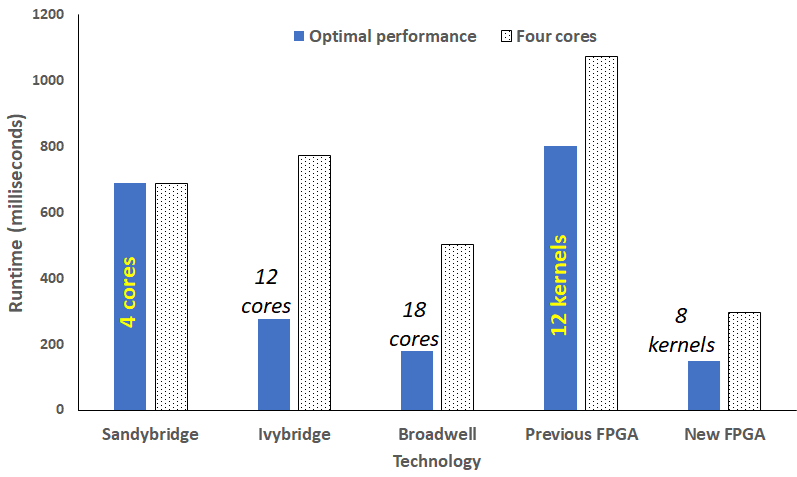 We explored the role of FPGAs to accelerate an advection scheme of MONC, an atmospheric model used by the Met Office, using HLS on an ADM8K5 FPGA card. The graph to the right illustrates a performance comparison between three CPU technologies and two versions our our FPGA approach (a previous slower version, and then one that we had fully optimised via HLS dataflow regions). It can be seen that eight FPGA kernels slightly outperforms 18 cores of Broadwell, by about 20%, but also the energy draw is less than a third that of the CPU. Eight of our optimised kernels was the most we could fit onto the ADM8K5, and when comparing 4 kernels against 4 CPU cores it can be seen that, like for like, the kernels are significantly faster.
We explored the role of FPGAs to accelerate an advection scheme of MONC, an atmospheric model used by the Met Office, using HLS on an ADM8K5 FPGA card. The graph to the right illustrates a performance comparison between three CPU technologies and two versions our our FPGA approach (a previous slower version, and then one that we had fully optimised via HLS dataflow regions). It can be seen that eight FPGA kernels slightly outperforms 18 cores of Broadwell, by about 20%, but also the energy draw is less than a third that of the CPU. Eight of our optimised kernels was the most we could fit onto the ADM8K5, and when comparing 4 kernels against 4 CPU cores it can be seen that, like for like, the kernels are significantly faster.
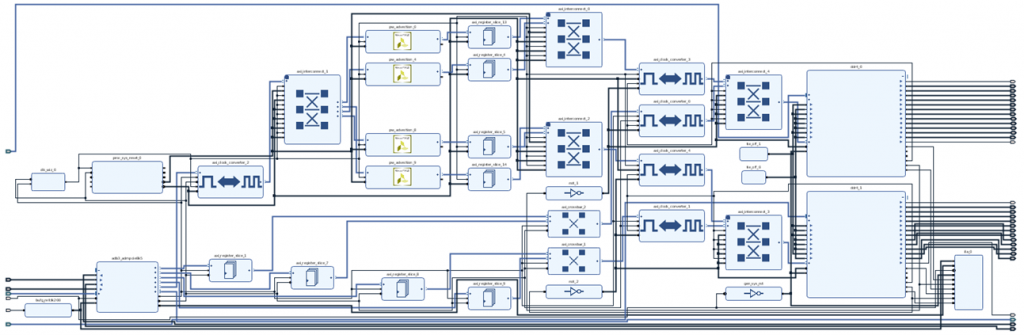
Following Xilinx’s high level productivity design methodology, the Fortran code was ported into HLS C++ and then the block design constructed from this. The block design itself is illustrated below, where on the left we have general infrastructure to connect to the host via PCIe, and on the right we have the infrastructure required to interact with the card’s 16GB DRAM (across two banks, each of the big IP blocks on the right are DRAM memory controllers) which holds the input data and results. Top middle are four of our advection IP blocks which have been exported from Vivado HLS, and the domain decomposed across these. More information can be found here, which represents work illustrated by the previous FPGA in the above graph, and we then undertook follow on work which focused specifically on techniques to reduce the cost of data movement, which resulted in significant performance improvements and more details are here.
Accelerating Nekbone’s CG solver
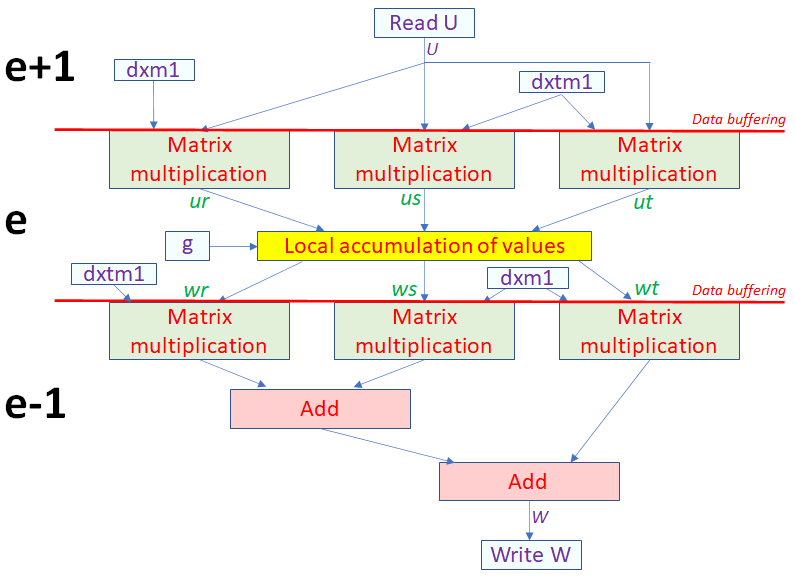 Nekbone, which represents the core computational pattern of Nek5000, is a popular HPC mini-app, and the vast majority of the runtime (over 75%) can be found within the AX kernel of the CG solver. We ported this to FPGAs, with the hypothesis being that on the CPU because this is fairly memory bound, by designing our memory access in a bespoke manner, then we could ameliorated this issue. For this work we used Xilinx’s Vitis platform and from the HLS kernel perspective this was quite a challenge, and we ended up adopting a dataflow architecture illustrated on the right, where the major computation required is a series of matrix multiplications, which can run concurrently and results then combined. However, due to data reordering requirements between different parts of the kernel and dependencies, to keep the entire dataflow pipeline busy we conceptually split it up across elements. Each element involves a number of grid points, up to around 4096, and the first part processes the next element, e+1, the middle part the current element,e, and the last part the previous element, e-1. Whilst this added significantly to the code complexity, there was over a 4000 times difference in performance between the first HLS version and the design illustrated on the right. Furthermore, with four kernels (the maximum we can fit onto the Alveo U280) we can out perform a 24-core Xeon Platinum (Cascade Lake) by over 4 times, and reach around 75% the performance of a V100 GPU (but at over twice the power efficiency). I think this illustrates that there are significant potential benefits to FPGAs, however one must adopt programming them in an entirely different, dataflow fashion.
Nekbone, which represents the core computational pattern of Nek5000, is a popular HPC mini-app, and the vast majority of the runtime (over 75%) can be found within the AX kernel of the CG solver. We ported this to FPGAs, with the hypothesis being that on the CPU because this is fairly memory bound, by designing our memory access in a bespoke manner, then we could ameliorated this issue. For this work we used Xilinx’s Vitis platform and from the HLS kernel perspective this was quite a challenge, and we ended up adopting a dataflow architecture illustrated on the right, where the major computation required is a series of matrix multiplications, which can run concurrently and results then combined. However, due to data reordering requirements between different parts of the kernel and dependencies, to keep the entire dataflow pipeline busy we conceptually split it up across elements. Each element involves a number of grid points, up to around 4096, and the first part processes the next element, e+1, the middle part the current element,e, and the last part the previous element, e-1. Whilst this added significantly to the code complexity, there was over a 4000 times difference in performance between the first HLS version and the design illustrated on the right. Furthermore, with four kernels (the maximum we can fit onto the Alveo U280) we can out perform a 24-core Xeon Platinum (Cascade Lake) by over 4 times, and reach around 75% the performance of a V100 GPU (but at over twice the power efficiency). I think this illustrates that there are significant potential benefits to FPGAs, however one must adopt programming them in an entirely different, dataflow fashion.
C bindings for the Pynq
 Xilinx’s Pynq is an SBC that aims to make the programming of FPGAs more accessible. In addition to the programmable logic, the attached Zynq 7020 also contains two ARM Cortex-A9 cores which run Linux, and Xilinx have provided Python bindings which are accessible via Jupyter notebooks. In the past couple of years my students and I have used this technology extensively for teaching and other projects, including running soft-cores, and found that it would be handy to have available C bindings for our uses. Therefore I wrote an open source library, pynq API, hosted at Github that provides such C bindings. The library is fairly simple and fully documented, and intended to be used as a replacement to the Python library if you are looking to interface with the Zynq in some other language. In addition to the core library, which loads the bitstream, and provides basic functionality such as MMIO, mapped shared memory, and GPIO, there is also an extensions API which provides support for functionality including AXI DMA and AXI interrupts.
Xilinx’s Pynq is an SBC that aims to make the programming of FPGAs more accessible. In addition to the programmable logic, the attached Zynq 7020 also contains two ARM Cortex-A9 cores which run Linux, and Xilinx have provided Python bindings which are accessible via Jupyter notebooks. In the past couple of years my students and I have used this technology extensively for teaching and other projects, including running soft-cores, and found that it would be handy to have available C bindings for our uses. Therefore I wrote an open source library, pynq API, hosted at Github that provides such C bindings. The library is fairly simple and fully documented, and intended to be used as a replacement to the Python library if you are looking to interface with the Zynq in some other language. In addition to the core library, which loads the bitstream, and provides basic functionality such as MMIO, mapped shared memory, and GPIO, there is also an extensions API which provides support for functionality including AXI DMA and AXI interrupts.