 I am a Work Package (WP) leader on the EU FET funded Visual Exploration and Sampling Toolkit for Extreme Computing (VESTEC) project. The aim of the project is to fuse HPC and real-time data for disaster response, and the COVID-19 global pandemic is an extreme example of the significant challenges associated with natural disasters. However, each year there are many more localised emergencies including wildfires, traffic accidents, disease, and extreme weather. Not only do these claim many lives annually, and result in significant economic impact, but furthermore with the rise of global issue such as climate change, are becoming more prevalent. As one strategy for tackling this, we believe there to be significant benefit in exploiting technological advances, such as supercomputing and the exponential growth in data capturing capabilities, to address such issues.
I am a Work Package (WP) leader on the EU FET funded Visual Exploration and Sampling Toolkit for Extreme Computing (VESTEC) project. The aim of the project is to fuse HPC and real-time data for disaster response, and the COVID-19 global pandemic is an extreme example of the significant challenges associated with natural disasters. However, each year there are many more localised emergencies including wildfires, traffic accidents, disease, and extreme weather. Not only do these claim many lives annually, and result in significant economic impact, but furthermore with the rise of global issue such as climate change, are becoming more prevalent. As one strategy for tackling this, we believe there to be significant benefit in exploiting technological advances, such as supercomputing and the exponential growth in data capturing capabilities, to address such issues.
The central idea of VESTEC is that front line responders will be able to make more accurate decisions if they can access data and predictions whilst tackling an emergency. This is boosted even further if they are able to quickly explore different scenarios, for instance testing different approaches to tackling the disaster, to enable the right decision to be made first time, every time. We have three use-cases in the research project; wild-fires, mosquito borne diseases, and space weather. I lead the interactive supercomputing work package, which is a central piece of the project, connecting the real-time data sources with the simulations themselves running on supercomputers.
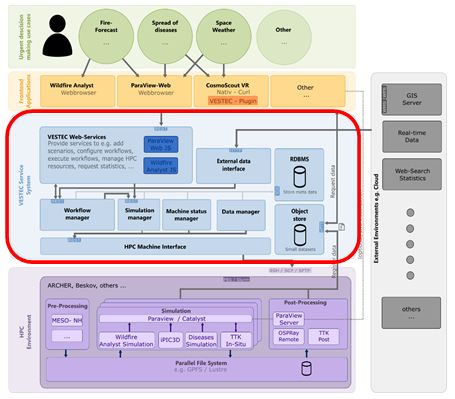 The diagram to the left illustrates the overall system architecture, with different partners responsible for different parts of this. The interactive supercomputing component is highlighted in red, above it the graphical interfaces of the urgent workloads, and beneath it the HPC machines themselves running all the different codes required. To the left are the real-time data sources, streaming data into the system which must be processed. In addition to the simulation codes themselves, for instance use-case specific models, there are also data analytics codes which perform activities including data visualisation and reduction. One major challenge from our perspective is that HPC machines were really not designed to be handling this urgent workload. This is not only because of the batch system (it is entirely pointless to wait for hours in the queue whilst the forest is burning!) but furthermore, HPC machines are not necessarily under the same availability requirements that would be expected by disaster response. To address this the project adopts a federation approach, where the central VESTEC system connects to a number of different HPC machines (the ambition being all the supercomputers of Europe) and is free to distribute workloads across these as required. Not only does this help with working around the batch queue system, as workloads can be split across machines that are currently underutilised, but it also enables the tracking of machine availability and avoiding those that have failed. More details on these general design decisions can be found here.
The diagram to the left illustrates the overall system architecture, with different partners responsible for different parts of this. The interactive supercomputing component is highlighted in red, above it the graphical interfaces of the urgent workloads, and beneath it the HPC machines themselves running all the different codes required. To the left are the real-time data sources, streaming data into the system which must be processed. In addition to the simulation codes themselves, for instance use-case specific models, there are also data analytics codes which perform activities including data visualisation and reduction. One major challenge from our perspective is that HPC machines were really not designed to be handling this urgent workload. This is not only because of the batch system (it is entirely pointless to wait for hours in the queue whilst the forest is burning!) but furthermore, HPC machines are not necessarily under the same availability requirements that would be expected by disaster response. To address this the project adopts a federation approach, where the central VESTEC system connects to a number of different HPC machines (the ambition being all the supercomputers of Europe) and is free to distribute workloads across these as required. Not only does this help with working around the batch queue system, as workloads can be split across machines that are currently underutilised, but it also enables the tracking of machine availability and avoiding those that have failed. More details on these general design decisions can be found here.
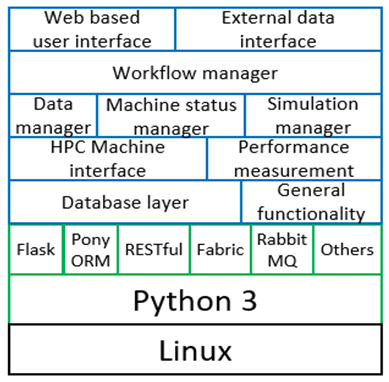 The technology stack of the VESTEC system is illustrated on the left, and a major aspect of this are workflows. We realised fairly early on that this would provide a nice way of expressing all the complex logic and decisions that need to be undertaken as a disaster unfolds. All use-cases are represented as workflows which are provided to the system and stages are then activated as appropriate, for instance by the arrival of data, completion of a simulation, or the availability of results. This was further complicated by the fact that none of the existing workflow technologies met our requirements, specifically the ability to compose stages dynamically and branch on conditions. This really surprised us, not least because of the plethora of existing workflow systems, and as such we developed an approach built upon RabbitMQ, where workflow stages are consumers of messages that arrive via queues and are activated on demand. More details around the technologies needed to build such a system could be found here.
The technology stack of the VESTEC system is illustrated on the left, and a major aspect of this are workflows. We realised fairly early on that this would provide a nice way of expressing all the complex logic and decisions that need to be undertaken as a disaster unfolds. All use-cases are represented as workflows which are provided to the system and stages are then activated as appropriate, for instance by the arrival of data, completion of a simulation, or the availability of results. This was further complicated by the fact that none of the existing workflow technologies met our requirements, specifically the ability to compose stages dynamically and branch on conditions. This really surprised us, not least because of the plethora of existing workflow systems, and as such we developed an approach built upon RabbitMQ, where workflow stages are consumers of messages that arrive via queues and are activated on demand. More details around the technologies needed to build such a system could be found here.
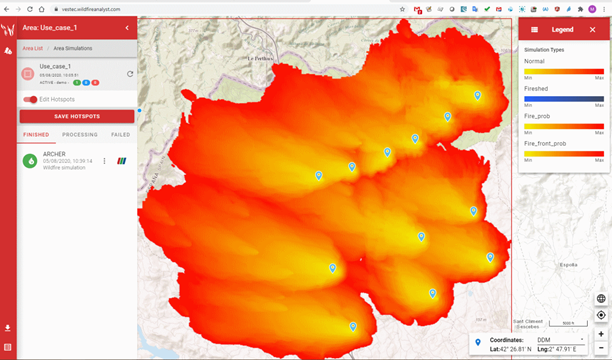
Wild-fires was the first use-case to be integrated with the system, and this is lead by VESTEC partner Technosylva who are the world’s leading company for the simulation of wild-fire progression. To the left is the GUI of their Wildfire Analyst, a commercial product developed by Technosylva and used throughout the world. This is connected to the VESTEC system and, using the results of simulations that are executing interactively on an HPC machine, enabling the operator to track the progression of fires. They can feed back modified observations from the field, known as hotspots, into the running simulations which will generate new scenario data. Fire progression is also governed by the weather forecast, and in VESTEC this is generated at very high resolution for the local area by running the Meso-NH weather model based on global GFS data.
UrgentHPC SC workshops
The use of HPC for urgent computing is still in its infancy, and as such we felt that an important part of the VESTEC project is around community building. I therefore led the organisation of the first and second international workshop on the use of HPC for urgent decision making at SuperComputing (SC). Building on a BoF at SC 2018, our first work shop ran at SC 2019 and we have a second one planned for 2020 later this year. The 2019 event was very successful, with six presented papers published in IEEE TCHPC, a keynote talk by the founder and CEO of Technosylva, and a panel comprising experts in the field. More details can be found here.