The use of mathematical models to make predictions based on existing data-sets is a hot topic at the moment, and with the exponential rise in available data and compute capabilities, some significant advances are being made in the machine learning field. I am especially interested in the application of machine learning to real-world problems, as well as the use of HPC to optimise these workloads.
Machine learning for oil and gas exploration
I was PI of the SWOOP project, funded by OGIC, which was a collaboration with Rock Solid Images (RSI) where we explored the application of machine learning to optimise petrophysical interpretation of well log data. These workflows involve taking the raw digital data collected from borehole drilling, and current practice is for experts to then manually interpret this and determine important factors, such as the mineralogy composition, porosity and saturation with hydrocarbons. Ultimately they are after an understanding of the area, and whether it is worth exploiting the wells to extract oil and gas. An example of the input curves for a well is illustrated below, where the top of the plot is the sea bed and it descends by depth. There are numerous values collected, but a challenge for ML is that this is typically noisy data, which can involve significant amounts of missing values.
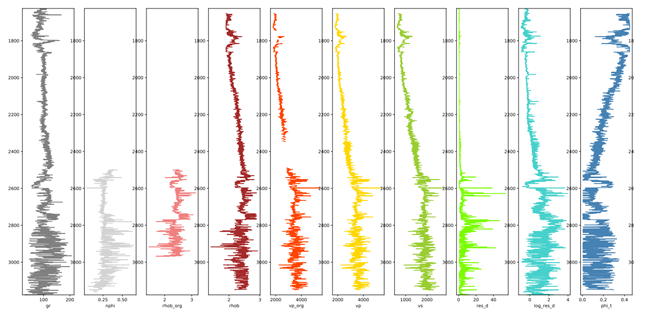
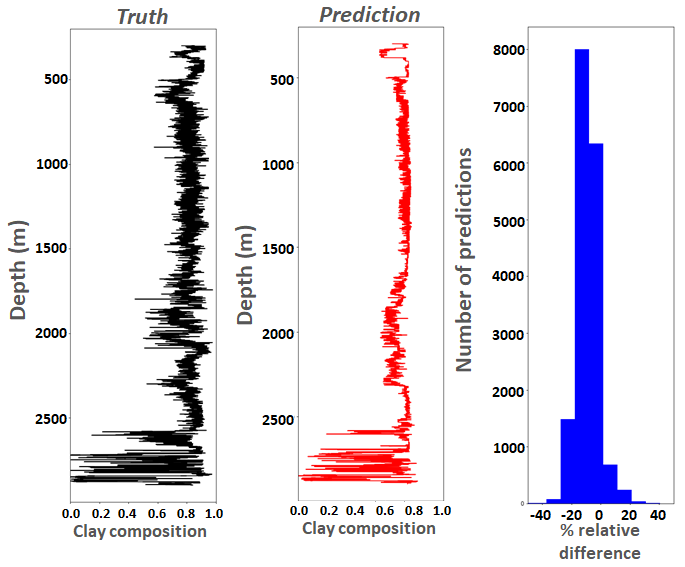 We used a boosted trees regression model, via the XGBoost package, to perform a full petrophysical interpretation using the raw well log data. We chose this approach specifically due to the missing data, and when compared against other approaches such as Deep Neural Networks (DDNs), boosted trees typically performed much better. Working with around 100 wells from the North Sea, models were trained on around three quarters of these, and then tested sight unseen against specific wells. The plot on the right illustrates the manually interpreted truth of clay content in black, against our model’s prediction in red. The rightmost histogram in blue illustrates the number of points that differ from the truth by a specific percentage. It can be seen that much of the general pattern of the lines is captured, but especially capturing some magnitudes is more challenging. Nonetheless, most differences are 20% or less than the truth values, and when one bears in mind that this can take an experienced petrophysicist around 20 hours, and our model less than second, then it really demonstrates the benefit of such an approach. Furthermore, the use of humans and machine learning is not mutually exclusive, for instance ML models can perform much of the grunt work, optimising the use of the human to perform refinement of the predictions, and also as a rought estimation that can help determine whether a full interpretation is worthwhile.
We used a boosted trees regression model, via the XGBoost package, to perform a full petrophysical interpretation using the raw well log data. We chose this approach specifically due to the missing data, and when compared against other approaches such as Deep Neural Networks (DDNs), boosted trees typically performed much better. Working with around 100 wells from the North Sea, models were trained on around three quarters of these, and then tested sight unseen against specific wells. The plot on the right illustrates the manually interpreted truth of clay content in black, against our model’s prediction in red. The rightmost histogram in blue illustrates the number of points that differ from the truth by a specific percentage. It can be seen that much of the general pattern of the lines is captured, but especially capturing some magnitudes is more challenging. Nonetheless, most differences are 20% or less than the truth values, and when one bears in mind that this can take an experienced petrophysicist around 20 hours, and our model less than second, then it really demonstrates the benefit of such an approach. Furthermore, the use of humans and machine learning is not mutually exclusive, for instance ML models can perform much of the grunt work, optimising the use of the human to perform refinement of the predictions, and also as a rought estimation that can help determine whether a full interpretation is worthwhile.
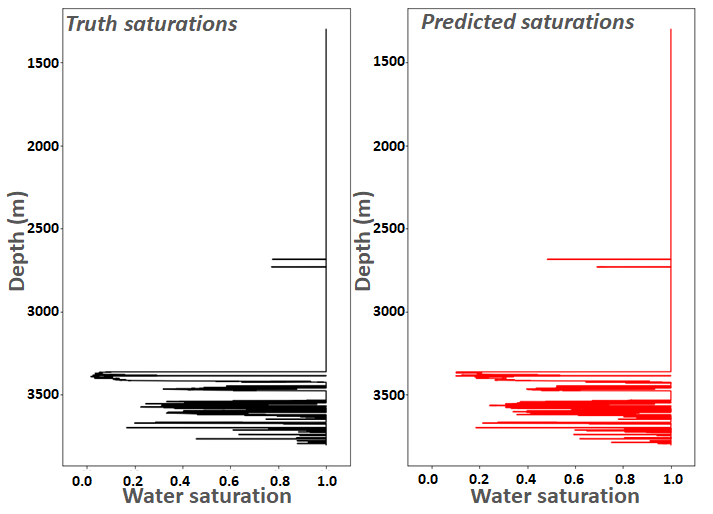 Some quantities are easier to predict than others, and for instance on the left we have the manually interpreted truth against model prediction of water saturation for a specific well. Fundamentally, what the petrophysicist is really interested in is whether the well is saturated with hydrocarbons, however unfortunately water is far more common than oil or gas, and as such we found that models tend to be much better at predicting it! Therefore, the best approach was to direct our models to predict water, and then invert this to result in the hydrocarbon saturation. It can be seen that this is reasonably accurate, with the majority of features picked up. Unlike the mineralogy, we found that using a mixture of models worked best here, relying on a DNN to classify whether it was oil or hydrocarbons, and then a boosted trees regression model to estimate the amount. By working in these two phases, we avoided numerous false positives. More details about this work can be found here.
Some quantities are easier to predict than others, and for instance on the left we have the manually interpreted truth against model prediction of water saturation for a specific well. Fundamentally, what the petrophysicist is really interested in is whether the well is saturated with hydrocarbons, however unfortunately water is far more common than oil or gas, and as such we found that models tend to be much better at predicting it! Therefore, the best approach was to direct our models to predict water, and then invert this to result in the hydrocarbon saturation. It can be seen that this is reasonably accurate, with the majority of features picked up. Unlike the mineralogy, we found that using a mixture of models worked best here, relying on a DNN to classify whether it was oil or hydrocarbons, and then a boosted trees regression model to estimate the amount. By working in these two phases, we avoided numerous false positives. More details about this work can be found here.
This project finished in 2019, however as of 2020 PGS have purchased the resulting IP, and we have undertaken a 6 month follow on project, to specialise the work to their wells and continue developing aspects to help improve prediction accuracy further
Reducing ensembles of geological models
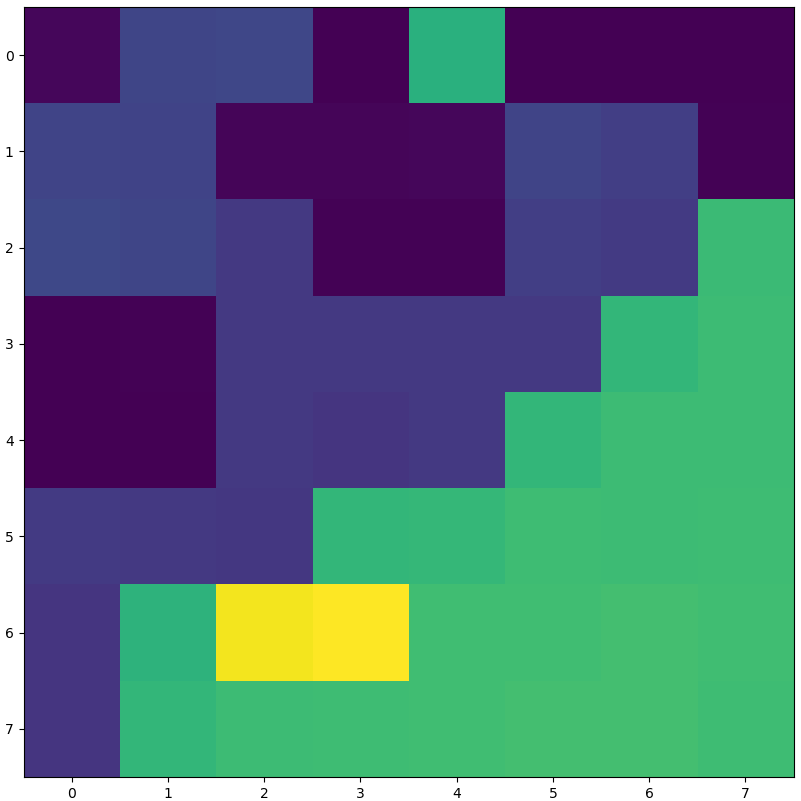 We also worked with Cognitive Geology which is an Edinburgh based company, to explore the use of machine learning to perform data reduction of a very large set of geological models, and to then work with this reduced set yet without missing any key features. These are known as black swan events, where assumptions around the data can miss important facets (in this case typically whether oil is present or not). We studied classification techniques which could identify different groupings of models, and found Self Organising Feature Maps (SOFM) to be optimal here, which are a form of artificial neural network that uses Kohonens learning rule and a competitive layer to perform unsupervised learning. A key question with SOFMs is the similarity metric between models, and we combined this classification technique with an approach that could predict Oil In Place (OIP) from a subset of the data. The image on the right is an illustration of the SOFM fitted to the data using values of OIP predicted by a gradient boosting regressor as the metric function. There are 64 squares here, which means 64 individual models, one from each cluster, are required to fully represent the oilfield. When one considers that this is less than 0.5% of the overall model set size, it is fairly impressive that such a significant data reduction can occur. More details about this work can be found here.
We also worked with Cognitive Geology which is an Edinburgh based company, to explore the use of machine learning to perform data reduction of a very large set of geological models, and to then work with this reduced set yet without missing any key features. These are known as black swan events, where assumptions around the data can miss important facets (in this case typically whether oil is present or not). We studied classification techniques which could identify different groupings of models, and found Self Organising Feature Maps (SOFM) to be optimal here, which are a form of artificial neural network that uses Kohonens learning rule and a competitive layer to perform unsupervised learning. A key question with SOFMs is the similarity metric between models, and we combined this classification technique with an approach that could predict Oil In Place (OIP) from a subset of the data. The image on the right is an illustration of the SOFM fitted to the data using values of OIP predicted by a gradient boosting regressor as the metric function. There are 64 squares here, which means 64 individual models, one from each cluster, are required to fully represent the oilfield. When one considers that this is less than 0.5% of the overall model set size, it is fairly impressive that such a significant data reduction can occur. More details about this work can be found here.
ML for lung cancer detection on micro-core architectures
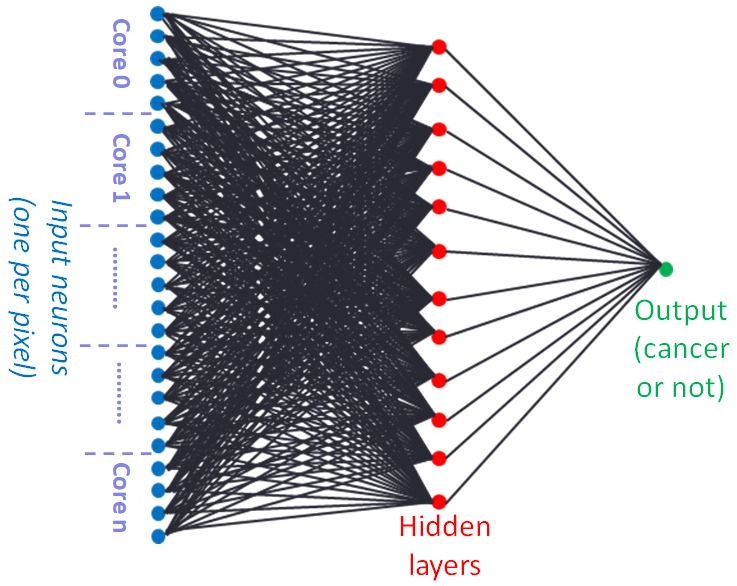 The Kaggle 2017 data science bowl involved the development of machine learning techniques for detecting lung cancer from 3D CT scans. We felt that this would be a very interesting test-case for our implementation of Python, ePython, on micro-core architectures, which combine many simple low-power CPU cores into a single package. A fairly simple neural network for classification was developed, where each neuron works on a pixel by pixel basis of the image and these are distributed across the micro-cores. The hypothesis was that, at reduced precision, the micro-cores could accelerate the linear algebra operations involved in model training and inference on the Epiphany-III. The entire data-set is around 10GB in size, with each image being typically between 60MB and 100MB. Bearing in mind each core has 32KB of local memory, and an entire memory space of maximum 32MB shared with the other cores, the work we completed on memory hierarchies (more details here) was a crucial enabler. The result was an approach which outperformed both CPython and native code execution on the host ARM CPU, and CPython on an Intel Broadwell CPU, although the Broadwell outperformed the micro-cores when run natively (albeit at significantly higher power consumption).
The Kaggle 2017 data science bowl involved the development of machine learning techniques for detecting lung cancer from 3D CT scans. We felt that this would be a very interesting test-case for our implementation of Python, ePython, on micro-core architectures, which combine many simple low-power CPU cores into a single package. A fairly simple neural network for classification was developed, where each neuron works on a pixel by pixel basis of the image and these are distributed across the micro-cores. The hypothesis was that, at reduced precision, the micro-cores could accelerate the linear algebra operations involved in model training and inference on the Epiphany-III. The entire data-set is around 10GB in size, with each image being typically between 60MB and 100MB. Bearing in mind each core has 32KB of local memory, and an entire memory space of maximum 32MB shared with the other cores, the work we completed on memory hierarchies (more details here) was a crucial enabler. The result was an approach which outperformed both CPython and native code execution on the host ARM CPU, and CPython on an Intel Broadwell CPU, although the Broadwell outperformed the micro-cores when run natively (albeit at significantly higher power consumption).