 Pretty much all major scientific discoveries in the past twenty or thirty years have, in some way, involved computation, and High Performance Computing (HPC) enables the study of such complex problems. However, fully exploiting supercomputers such as ARCHER (the UK national supercomputer) on the right, raises a set of unique challenges that range from the applications space, through the programming models, all the way down to the hardware itself. Being based at EPCC, which is the UK’s leading centre for HPC and amongst other things hosts the UK national supercomputer, I have worked on numerous research projects across these different spaces.
Pretty much all major scientific discoveries in the past twenty or thirty years have, in some way, involved computation, and High Performance Computing (HPC) enables the study of such complex problems. However, fully exploiting supercomputers such as ARCHER (the UK national supercomputer) on the right, raises a set of unique challenges that range from the applications space, through the programming models, all the way down to the hardware itself. Being based at EPCC, which is the UK’s leading centre for HPC and amongst other things hosts the UK national supercomputer, I have worked on numerous research projects across these different spaces.
Met Office NERC Cloud model (MONC)
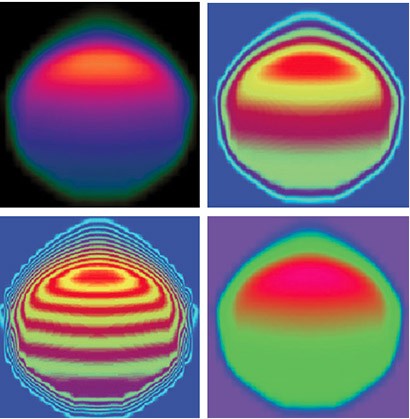 In 2014 I started on a collaboration with the Met Office to develop a new Large Eddy Simulation (LES) code, and for this to replace their existing high resolution atmospheric model from the 1990s. The idea was not only to optimise the code itself, but also develop a new model that would scale across the thousands of cores which comprise modern HPC machines. Designed with most of the science and parallel functionality provided as a set of independent plugins, this is a toolkit for atmospheric science which can be used for many different types of problems. In addition to MONC itself, we also ported aspects to GPUs (more details) and FPGAs (more details). The images to the left show the same simulation in MONC of a bubble of warm air rising through the atmosphere, with different filters applied. This is one of the standard test-cases and to begin with the bubble was warmest in the middle, with the warmer, less dense, air has rising up faster (higher) than the surrounding cooler, more dense, air as the simulation progresses.
In 2014 I started on a collaboration with the Met Office to develop a new Large Eddy Simulation (LES) code, and for this to replace their existing high resolution atmospheric model from the 1990s. The idea was not only to optimise the code itself, but also develop a new model that would scale across the thousands of cores which comprise modern HPC machines. Designed with most of the science and parallel functionality provided as a set of independent plugins, this is a toolkit for atmospheric science which can be used for many different types of problems. In addition to MONC itself, we also ported aspects to GPUs (more details) and FPGAs (more details). The images to the left show the same simulation in MONC of a bubble of warm air rising through the atmosphere, with different filters applied. This is one of the standard test-cases and to begin with the bubble was warmest in the middle, with the warmer, less dense, air has rising up faster (higher) than the surrounding cooler, more dense, air as the simulation progresses.
The model is extensively used by the Met Office, as well as UK atmospheric researchers more generally. One of the most innovative aspects is our approach to data analytics, where scientists are often not interested in the (very large) amounts of raw data but instead in high level information that can be derived from them. Whilst previous generations of models would process the data inline with computation, this was quite a bottleneck and-so we adopted an in-situ approach, where cores are shared between data analytics and computation. More details about MONC can be found here.
In addition to MONC, we also focused on optimising CASIM, which is a microphysics code developed by the Met Office and used extensively as a sub-component to many other models. In addition to this optimisation, we also ported the code to GPUs and KNLs, with more details here.
BGS Model of the Earth’s Magnetic Environment
 I worked on modernising and optimising the BGS’s Model of the Earth’s Magnetic Environment (MEME) as part of an eCSE project. This code predicts the earth’s geomagnetic field, which can fluctuate specifically year by year in some locations, and is an important component of other BGS models. The results of which are used extensively, from oil and gas exploration to map orientation in every Google Android mobile phone. Simulations rely on data from ground observation sites and satellites, using this to build a matrix and RHS, which is then fed into an Eigen solver to solve a series of linear equations. The matrix building is potentially very expensive (many hours), and whilst the code had been parallelised, load balancing was poor and the Eigen solve itself was sequential. In-fact the later limitation was most severe, as it meant the maximum amount of data that could be used by the model was fundamentally limited by a single node’s memory space. This meant that only around one in twenty input values could be processed, which limited accuracy.
I worked on modernising and optimising the BGS’s Model of the Earth’s Magnetic Environment (MEME) as part of an eCSE project. This code predicts the earth’s geomagnetic field, which can fluctuate specifically year by year in some locations, and is an important component of other BGS models. The results of which are used extensively, from oil and gas exploration to map orientation in every Google Android mobile phone. Simulations rely on data from ground observation sites and satellites, using this to build a matrix and RHS, which is then fed into an Eigen solver to solve a series of linear equations. The matrix building is potentially very expensive (many hours), and whilst the code had been parallelised, load balancing was poor and the Eigen solve itself was sequential. In-fact the later limitation was most severe, as it meant the maximum amount of data that could be used by the model was fundamentally limited by a single node’s memory space. This meant that only around one in twenty input values could be processed, which limited accuracy.
We replaced the Eigen solver with SLEPc, which is an extension for PETSc providing Eigen solver functionality. Furthermore, the code was significantly optimised and modernised, moving from fixed-form Fortran 77 to Fortran 2003. The matrix (and RHS, although that was far smaller) was decomposed across MPI processes, and as the matrix is symmetric then only the diagonal and upper cells need to be calculated. This is a very important property because of the high computational cost involved in calculating each cell, and as such when decomposing the matrix it was still important exploit this, but to do so in a way that was well balanced to avoid overhead. We therefore developed an approach to implicitly building symmetric decomposed matricies, as illustrated below.
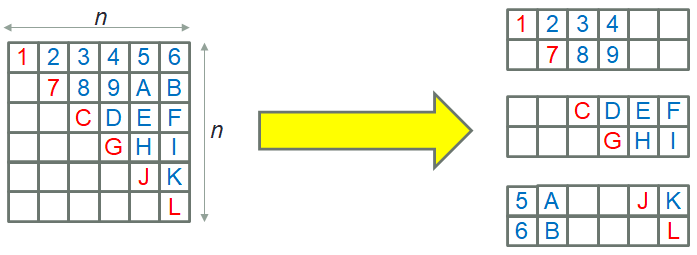
Ultimately, this work reduced the execution time of the model by around 294 times for existing tests, reducing runtime of existing system from hours to minutes. Furthermore, this work also provided the ability to model much larger system sizes, where up to 100,000 model coefficients were demonstrated, with the previous limit being around 10,000. More details about this work can be found here.
Programming models for HPC
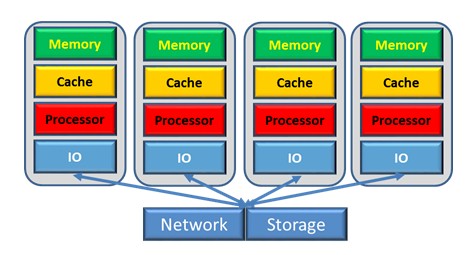 One of the interesting challenges in HPC is how we write parallel and highly scalable code, especially when one considers the prevalence of heterogeneous architectures. Whilst much work has been done around novel languages, still the vast majority of HPC programmers write their code using either C/C++ or Fortran, with MPI and/or OpenMP. Whilst this is understandable from the perspective of performance, writing parallel codes in languages that were designed for sequential work raises numerous disadvantages. I am interested in novel abstractions that can impact the way in which we write parallel codes, and worked on an approach that uses the type system, called type oriented programming, to express the vast majority of parallelism. Separately, I also developed a 24KB implementation of Python known as ePython for micro-cores which was shipped with all Parallella SBCs, and explored the abstractions necessary for offloading code and data to this technology. A task-based approach to writing parallel codes is a very interesting area, and I developed a lightweight tasking framework called EDAT which enables the development of highly asynchronous applications over distributed memory architectures.
One of the interesting challenges in HPC is how we write parallel and highly scalable code, especially when one considers the prevalence of heterogeneous architectures. Whilst much work has been done around novel languages, still the vast majority of HPC programmers write their code using either C/C++ or Fortran, with MPI and/or OpenMP. Whilst this is understandable from the perspective of performance, writing parallel codes in languages that were designed for sequential work raises numerous disadvantages. I am interested in novel abstractions that can impact the way in which we write parallel codes, and worked on an approach that uses the type system, called type oriented programming, to express the vast majority of parallelism. Separately, I also developed a 24KB implementation of Python known as ePython for micro-cores which was shipped with all Parallella SBCs, and explored the abstractions necessary for offloading code and data to this technology. A task-based approach to writing parallel codes is a very interesting area, and I developed a lightweight tasking framework called EDAT which enables the development of highly asynchronous applications over distributed memory architectures.